import pandas as pdThis post will review some frequent tasks in Python.
Create dataframe from scratch
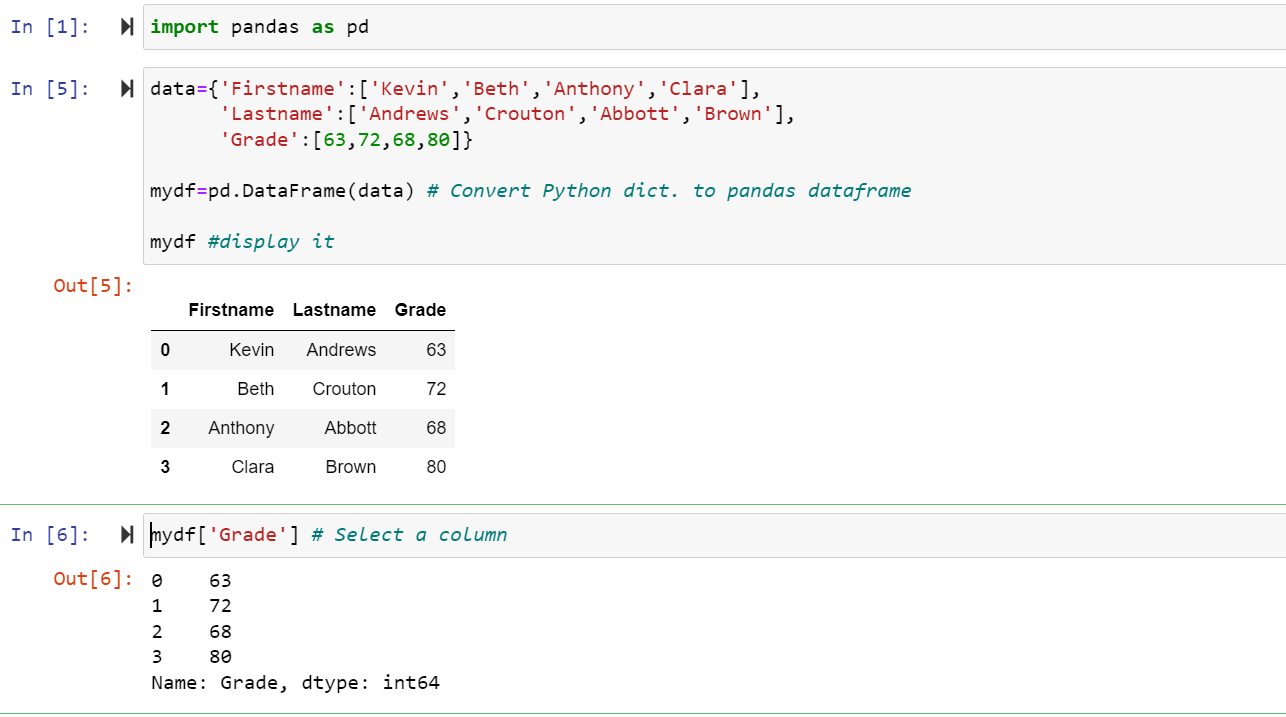
You may want to create a simple dataframe manually, as follows.
You will first need to have Python and pip installed, for using packages such as pandas and csv.
Then a custom dataframe can be created:
# 'Dictionary of lists' method.
data={'Firstname':['Kevin','Beth','Anthony','Clara'],
'Lastname':['Andrews','Crouton','Abbott','Brown'],
'Grade':[65,72,70,80]}
mydf=pd.DataFrame(data) # Convert Python dict. to pandas dataframe
mydf #display it # any name possible| Firstname | Lastname | Grade | |
|---|---|---|---|
| 0 | Kevin | Andrews | 65 |
| 1 | Beth | Crouton | 72 |
| 2 | Anthony | Abbott | 70 |
| 3 | Clara | Brown | 80 |
Alternatively, a dataframe can be constructed from a list of lists:
import pandas as pd
data=[['Kevin', 'Andrews', 65],
['Beth', 'Crouton', 72],
['Anthony', 'Abbott', 70],
['Clara', 'Brown', 80]]
mydf=pd.DataFrame(data,columns=['FirstName', 'LastName', 'Grade']) # name variables
mydf # display| FirstName | LastName | Grade | |
|---|---|---|---|
| 0 | Kevin | Andrews | 65 |
| 1 | Beth | Crouton | 72 |
| 2 | Anthony | Abbott | 70 |
| 3 | Clara | Brown | 80 |
Add custom row indexes with:
mydf = pd.DataFrame(data,
columns=['FirstName', 'LastName', 'Grade'],
index=['St1', 'St2', 'St3', 'St4'])
mydf # view| FirstName | LastName | Grade | |
|---|---|---|---|
| St1 | Kevin | Andrews | 65 |
| St2 | Beth | Crouton | 72 |
| St3 | Anthony | Abbott | 70 |
| St4 | Clara | Brown | 80 |
The section above is taken largely from https://www.tutorialspoint.com/how-to-create-a-dataframe-in-python, with outdated Pandas function ‘dataframe’ updated to correct it.
Save a dataframe to file
Once in Pandas (“pd”) dataframe format, write the dataframe (here called “mydf” but any name is possible) with:
mydf.to_csv("mydf.csv", encoding='utf-8')
Open a dataframe from file
More commonly, you may have a csv containing information that you want to open.
Read it in with:
import csv
with open('mydf.csv', newline='') as f:
reader = csv.reader(f) # temporary object
docdf = [tuple(row) for row in reader] #tuple format as a list would be nested
docdf # View tuple version[('', 'FirstName', 'LastName', 'Grade'),
('St1', 'Kevin', 'Andrews', '65'),
('St2', 'Beth', 'Crouton', '72'),
('St3', 'Anthony', 'Abbott', '70'),
('St4', 'Clara', 'Brown', '80')]# Turn tuple version back into Pandas df. Simple version with manually entered variable names:
docdf2 = pd.DataFrame(docdf, columns = ['Index', 'FirstName', 'LastName', 'Grade'])
docdf2 # View| Index | FirstName | LastName | Grade | |
|---|---|---|---|---|
| 0 | FirstName | LastName | Grade | |
| 1 | St1 | Kevin | Andrews | 65 |
| 2 | St2 | Beth | Crouton | 72 |
| 3 | St3 | Anthony | Abbott | 70 |
| 4 | St4 | Clara | Brown | 80 |
If needed, cut an extra header row out of the dataframe with:
docdf2 = docdf2[1:] #Keep row 1 (Python row 1, ie row 2) onward.
docdf2 # View| Index | FirstName | LastName | Grade | |
|---|---|---|---|---|
| 1 | St1 | Kevin | Andrews | 65 |
| 2 | St2 | Beth | Crouton | 72 |
| 3 | St3 | Anthony | Abbott | 70 |
| 4 | St4 | Clara | Brown | 80 |
# Or, to use the first row as the column/variable names:
docdf2 = pd.DataFrame(docdf[1:], #pull content from 2nd row on
columns = docdf[0]) #pull headers from 1st row
docdf2 # View (same result, other than un-named Index column now)| FirstName | LastName | Grade | ||
|---|---|---|---|---|
| 0 | St1 | Kevin | Andrews | 65 |
| 1 | St2 | Beth | Crouton | 72 |
| 2 | St3 | Anthony | Abbott | 70 |
| 3 | St4 | Clara | Brown | 80 |
Select a column/variable in your dataframe
# By name
mydf['Grade']St1 65
St2 72
St3 70
St4 80
Name: Grade, dtype: int64
Select a row from the dataframe:
mydf[2:3] # Select only row 3
#(I.e.: Python numbered row 2, as numbering starts as 0, 1, 2)
# And as the first number in a range is inclusive (2:3 includes 2)
# But as the last number in a range is inclusive (2:3 excludes 3)
# Variations: [2:] will select all rows from 2 onward; [2:4] will select 2 and 3; etc.| FirstName | LastName | Grade | |
|---|---|---|---|
| St3 | Anthony | Abbott | 70 |
Select rows based on information in a column
Use df.loc, similar to R’s which() function.
# Use df.loc to select rows based on information in a column:
mydf.loc[mydf['Grade'] == 80]| FirstName | LastName | Grade | |
|---|---|---|---|
| St4 | Clara | Brown | 80 |
mydf.loc[mydf['Grade'] <= 70]| FirstName | LastName | Grade | |
|---|---|---|---|
| St1 | Kevin | Andrews | 65 |
| St3 | Anthony | Abbott | 70 |
Other variations
# Is not
mydf.loc[mydf['Grade'] != 70]| FirstName | LastName | Grade | |
|---|---|---|---|
| St1 | Kevin | Andrews | 65 |
| St2 | Beth | Crouton | 72 |
| St4 | Clara | Brown | 80 |
# Two conditions
mydf.loc[(mydf['Grade'] >= 70) & (mydf['Grade'] < 80)]| FirstName | LastName | Grade | |
|---|---|---|---|
| St2 | Beth | Crouton | 72 |
| St3 | Anthony | Abbott | 70 |
# Condition is in a range of values, presented as a list:
mydf.loc[mydf['FirstName'].isin(['Anthony', 'Beth'])]| FirstName | LastName | Grade | |
|---|---|---|---|
| St2 | Beth | Crouton | 72 |
| St3 | Anthony | Abbott | 70 |
# Condition is in a range of values, numeric
mydf.loc[mydf['Grade'].isin([70, 72, 80])]
# Note that this doesn't work well for an inclusive range of integers;
# use a 2-part statement with less than [number x] and more than [number y] for that.| FirstName | LastName | Grade | |
|---|---|---|---|
| St2 | Beth | Crouton | 72 |
| St3 | Anthony | Abbott | 70 |
| St4 | Clara | Brown | 80 |
Turn a column of dataframe into a list:
doclist = docdf2['FirstName'].tolist()
doclist['Kevin', 'Beth', 'Anthony', 'Clara']Alternatively, we can turn an element of the original tuples object ‘docdf’ to a list
doclist = [x[1] for x in docdf] #2nd element of each row to list; un-nest
doclist = doclist[1:] # cut out first element
doclist['Kevin', 'Beth', 'Anthony', 'Clara']
Un-nest a nested list:
mylist = [[1,2], [3,4]]
mylist # view[[1, 2], [3, 4]]mylist_unnested = [item for sublist in mylist for item in sublist]
# Edit out 'item' and 'sublist' for any words here;
# 'mylist' in the middle must be your original list's name, though.
mylist_unnested # view[1, 2, 3, 4]
Compare by selecting one item from the list:
mylist[0] # first element[1, 2]mylist_unnested[0] # first element1These are some of my most-used functions. Enjoy!